 Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
Rによるデータ分析
クロス集計 や 分割表 は、単に集計の方法というだけでなく、 対数線形分析 のように、集計したデータを分析の対象にする方法もあります。
クロス集計 をRで作る時の実施例です。
この例では、Cドライブの「Rtest」というフォルダに、 「Data.csv」という名前で下記のようなデータが入っている事を想定しています。 この例では、元データの3列目が量的データで、1列目2列目が質的データとして処理されます。
1列目と2列目の組合せの数だけ、平均値が計算されます。 meanをsdにすると標準偏差が計算されます。
setwd("C:/Rtest")
Data <- read.csv("Data.csv", header=T)
aggregate(Data[,3]~Data[,1]*Data[,2],data=Data,FUN=mean)
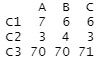
分割表 をRで作る時の実施例です。
setwd("C:/Rtest")
Data <- read.csv("Data.csv", header=T)
table(Data[,1], Data[,2])
質的変数を縦と横に並べずに集計する方法です。 対数線形分析 をする時には、この形に集計しておく必要があります。
dplyrのインストールが事前に必要です。
library(dplyr)
setwd("C:/Rtest")
Data <- read.csv("Data.csv", header=T)
count(group_by(Data,Data[,1:2],.drop=FALSE))

「.drop=FALSE」がないと、条件の組合せに当てはまるものがない時に「0」が出力されません。
下記は、量的変数があった場合に、
1次元クラスタリング
で質的変数(区間のデータ)に変換する技も入った場合です。
library(dplyr)
setwd("C:/Rtest")
Data <- read.csv("Data.csv", header=T)
for (i in 1:ncol(Data)) {
if (class(Data[,i]) == "numeric") {
Data[,i] <- droplevels(cut(Data[,i], breaks = 3,include.lowest = TRUE))# 3分割する場合。量的データは、質的データに変換
}
}
count(group_by(Data,Data[,1:3],.drop=FALSE))

